AWS 데이터 분석을 위한 AI/ML
파이썬 라이브러리와 AWS Athena, QuickSight, EMR, Spark로 데이터를 처리, 분석, 시각화하여 ML 모델링에 필요한 인사이트를 얻습니다.
개요
누락된 데이터를 처리하는 방법과 데이터 안의 아웃라이어를 처리하는 방법, 데이터를 머신러닝 알고리즘에 맞게 변환, 인코딩하는 방법이 필요합니다. Scikit-learn, Athena, Quicksight, MapReduce, Apache Spark를 통해 데이터에 대한 인사이트를 얻을 수 있습니다.
Python
머신러닝과 데이터 과학에서 파이썬은 필수적인 언어가 되어가고 있습니다.
어떻게 사용되는지, 그 안에서 사용되는 다양한 구성요소와 서로 무엇을 위해 사용되는지가 중요합니다.
matplotlib numpy pandas
Pandas
- 데이터를 자르고 조작하는 라이브러리입니다.
- 데이터를 탐색하고, 뭐가 있는지, 다른 열에 어떤 값이 있는지 확인할 수 있고 아웃라이어를 다룰 수 있습니다.
Pandas 의 핵심으로 Data Frames가 있습니다.Data Frame은 Table이며 데이터의 행과 열을 조작할 수 있게 해줍니다. > Excel 스프레드시트와 유사합니다.Series Data Frame의 일차원 구조입니다.Row를 Series로 추출할 수 있습니다.Numpy 와 연동하면Numpy 배열을Pandas에 가져오고 반대로Numpy로 Export 할 수 있습니다.
Numpy
- low 레벨 라이브러리로 파이썬에서 데이터 배열을 다루는 라이브러리입니다.
- 머신러닝 알고리즘으로 데이터를 넘기기 전 포맷을 거치는 경우에 사용합니다.
Pandas로 가져와서 데이터를 조작하고 정리한 후 Numpy배열로 보내면 머신러닝 알고리즘에 입력으로 사용할 수 있게 됩니다.
matplotlib
- Pandas의 Data Frame이나 숫자 배열로 데이터를 시각화하는 기본적인 방법입니다.
- 데이터 시각화와 아웃라이어 시각화에 유용하게 사용할 수 있습니다.
- 데이터가 어떻게 분포되었는지, 얼마나 많은 예외가 있는지 확인할 수 있습니다.
- 히스토그램같은 방식과 binning 등 여러가지 범위로 묶어 시각화할 수 있습니다.
Seaborn
- matplotlib에 비해 손쉽게 그래프를 그리고 그래프 스타일 설정할 수 있습니다.
- 훨씬 더 스타일있고 융통성있게 시각화가 가능합니다.
- 시각화 방식에는 여러가지가 존재합니다. → https://m.blog.naver.com/so15284/221629961411
- 히트맵, 페어플롯, 조인트플롯 등이 있으며 어떤 상황에 사용되는지 이해가 필요합니다.
Scikit_learn
- 머신러닝 모델의 파이썬 라이브러리입니다.
- 데이터를 탐색하면서 다양한 알고리즘을 실험해볼 수 있습니다. 이를 통해 데이터에 변화를 줄 떄 머신이 어떻게 반응하는지를 확인할 수 있습니다.
- 비슷해보이는 코드와 환경을 사용해 여러 알고리즘을 돌려가며 테스트할 수 있습니다.
- 데이터 준비와 분석의 관련된 사전 처리 기능도 포함됩니다.
- 사이킷런의 사전 처리 모듈을 이용해 모든 기능 데이터를 정상적인 분포로 확장시킵니다.
Jupyter notebooks
Jupyter notebook은 웹 브라우저에서 실행되며 파이썬 환경에서 실행되는 서버와 통신합니다.
대표적으로 아나콘다가 있으며, 실제로 머신러닝 모델을 훈련시키고 그 모델을 배포할 수 있는 환경을 만들 수 있습니다.
사전처리를 통해 각각의 값들이 같은 범위를 가질 수 있도록 스케일 조정
from sklearn import preprocessing
scaler = preprocessing.StandardScaler()
all_features_scaled = scaler.fit_transform(all_features)
all_features_scaled
array([[ 0.7650629 , 0.17563638, 1.39618483, 0.24046607],
[ 0.15127063, 0.98104077, 1.39618483, 0.24046607],
[-1.89470363, -1.43517241, -1.157718 , 0.24046607],
...,
[ 0.56046548, 0.98104077, 1.39618483, 0.24046607],
[ 0.69686376, 0.98104077, 1.39618483, 0.24046607],
[ 0.42406719, 0.17563638, 0.11923341, 0.24046607]])데이터의 타입
어떤 종류의 데이터를 다루는지 아는건 중요하며 기술마다 다루는 데이터의 종류와 상황에 따른 뉘앙스가 다를 수 있습니다.
데이터의 주요 유형
사용하는 데이터의 유형에 따라 머신러닝 모델을 만드는데 사용하는 알고리즘 또한 달라지게 됩니다.
- Numerical(수치)
- Categorical(범주)
- Ordinal(서수 - 순서형)
Numerical Data
일반적인 데이터 타입으로 측정할 수 있으며, 수량화 가능한 걸 나타냅니다.
대표적으로 사람들의 키, 주가, 페이지 로딩 시간 등등이 있으며 측정할 수 있고 가능성의 폭이 넓은 것들을 일컫습니다.
Discrete data(이산형 데이터)
측정된 변수값이 이산적인 값을 갖는 데이터로 특정 정수로 맞아떨어지는 경우를 의미합니다.
소수점으로 표현될 수 없는 값을 의미하기도 합니다.ex) 인구 수, 도서관의 도서 수 등 개별적이며 분리된 값을 의미합니다.
Continuous Data
분수로 분류할 수 있는 무한한 가능성의 값들을 의미하며 연속 데이터 집합입니다. 혹은 미세하게 다른 값들을 얻을 수 있는 데이터를 의미하기도 합니다.
ex) 사람의 키 등 셀 수 없는 자료형을 의미하기도 합니다.
Categorical
고유 숫자 의미가 전혀 없는 데이터로 하나의 카테고리를 다른 카테고리와 비교할 수 없습니다.
숫자를 할당할 수 있지만 전혀 의미없는 임시의 데이터로 활용하며 카테고리를 간략히 표현하기 위해 사용되기도 합니다. 단순히 데이터를 나누는 방식일 뿐입니다.
ex) 성별, 예/아니오, 인종 등등이 있습니다.
Ordinal
숫자와 범주적 자료가 뒤섞여 있습니다.
숫자가 수학적 의미가 있으며, 서로 비교할 수 있습니다. 숫자와 연관된 여러 카테고리가 있기 때문에 카테고리 데이터가 수학적 의미를 가지고 있습니다.
ex) 영화 리뷰(1~5)
데이터 분포
데이터가 특정 범위로 나뉠 가능성을 나타내며, 데이터 세트의 주요 특성을 파악하는 탐색적 데이터 분석 (Exploratory Data Analysis/EDA)을 이해할 때 중요합니다.
정규 분포(normal distribution)
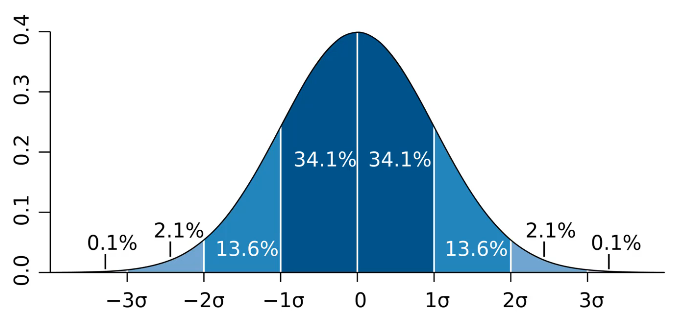
정규 분포는 연속 확률 분포의 한 예로, 데이터 포인트가 평균(μ) 주위에 대칭적으로 분포되어 있고, 평균으로부터의 거리에 따라 발생 확률이 감소하는 ’종모양’의 그래프를 형성합니다.
확률 밀도 함수의 한 가지 예시로, 정규 분포의 확률 밀도 함수는 데이터 포인트가 특정 값 근처에 있을 확률을 설명합니다.
연속 데이터는 데이터 포인트가 무한대(0.0000000000..001)가 될 수 있습니다. 아주 특정한 값이 발생할 확률은 매우 낮기 때문에, 확률 밀도 함수는 특정 범위의 값이 발생할 확률을 알려주는 것이라고 생각할 수 있습니다.
연속 데이터에 사용됩니다. 이는 측정값이 특정 범위 내의 어떤 값이든 취할 수 있음을 의미합니다 (예: 사람의 키, 온도 등).
또한 정규 분포는 자연 현상, 사회 과학, 심리학 등 다양한 분야에서 관찰되는 많은 현상을 모델링하는 데 사용됩니다. 그 외에도 중심극한정리에 의해, 여러 독립적인 확률 변수의 합(또는 평균)은 샘플 크기가 충분히 크면 정규 분포에 가까워진다는 점에서 통계적 추론에 있어 근본적인 역할을 합니다.
정리하면 주어진 데이터 포인트가 발생할 확률을 시각화하는 방법입니다.
확률 질량 함수
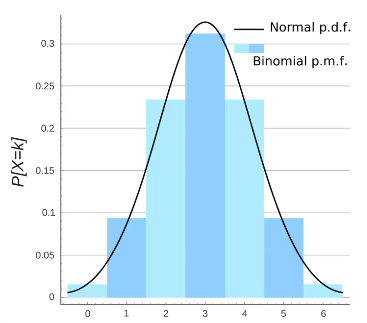
특정 데이터가 발생할 가능성을 시각화하는 방법으로 히스토그램과 유사합니다.
확률 질량 함수는 이산 데이터에 대해 사용되며 각 이산 값에 대한 확률을 나타내는 막대 그래프로 시각화됩니다.
정리하면 데이터 집합에서 특정 값이 발생할 확률이며 대표적인 예시로 푸아송 분포가 있습니다.
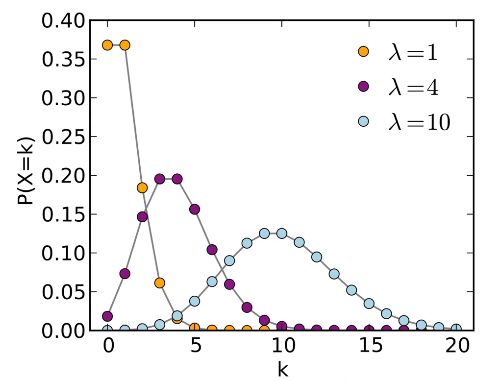
이 분포는 평균 발생률(λ, 람다)이 알려진 경우, 드물게 발생하는 사건(k)의 확률을 계산할 때 유용합니다.
한 카페에서 일하고 있다고 합시다. 이 카페에는 평균적으로 한 시간에 2명의 손님이 방문합니다. 여기서 “평균적으로 한 시간에 2명”이라는 정보가 바로 푸아송 분포에서의 λ(람다) 값입니다. 이제, “다음 시간에 정확히 4명(k)의 손님이 올 확률은 얼마인가?“라는 질문에 답하기 위해 푸아송 분포를 사용할 수 있습니다.
from math import exp, factorial
# Given values
lambda_val = 2 # 평균 방문 손님 수 (λ)
k = 4 # 특정 시간 동안의 손님 수 (k)
# Poisson distribution formula to calculate the probability
probability = (exp(-lambda_val) * lambda_val**k) / factorial(k)
probability어느 산골짜기 보건소에는 환자가 자주 오지 않아서 한산하다. 하루 평균 3명의 환자가 내원한다고 했을 때, 하루에 두 명 이상의 환자가 내원할 확률은?
# Given values for the new scenario
lambda_val_new = 3 # 하루 평균 환자 수
# Calculate the probabilities for 0 and 1 patient(s)
prob_0 = (exp(-lambda_val_new) * lambda_val_new**0) / factorial(0)
prob_1 = (exp(-lambda_val_new) * lambda_val_new**1) / factorial(1)
# Calculate the probability for two or more patients
prob_2_or_more = 1 - (prob_0 + prob_1)
prob_2_or_more이항 분포
예/아니오로 대답하는 실험의 연속에서 성공 횟수를 설명하는 것입니다.
베르누이 분포
이항 분포의 특수한 경우로 표본 데이터가 하나 뿐이면 베르누이 분포, 표본 데이터가 여러개가 되면 이항 분포가 됩니다.
즉 베르누이 분포의 총 합은 이항 분포라고 생각할 수 있습니다.
Time series analysis
시계열분석으로 일련의 데이터 포인트(연속적인 데이터)와 유사합니다.
표본은 일정 기간동안 수집되어 특정한 데이터의 패턴을 보여주게 됩니다.
Trend
장기간에 걸쳐 시계열 데이터가 상대적으로 높거나 낮은 값으로 이동하는 것을 보여주는 데이터 패턴입니다. 일반적으로는 일정 기간 동안만 발생했다가 사라지며 반복되지 않습니다.
Seasonality
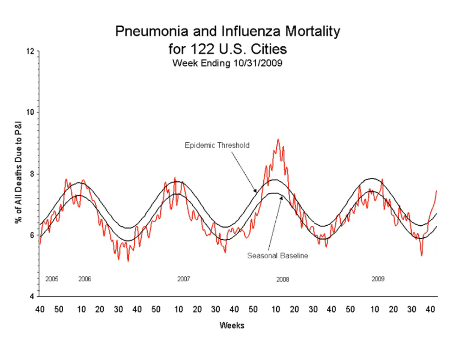
데이터 패턴으로 계절적 요소가 반영됩니다.
시기, 월, 주 단위로 분류가 가능하며 반복적인 패턴을 보이게 됩니다.
Noise
시간 시리즈의 일부로 계절에 따른 유행 뿐만 아니라 자연에서 일어나는 랜덤성 있는 데이터를 포함합니다.
Additive model
Seasonality + Trends + Noise는 전체적인 시간 기록을 나타내기도 하며 선형적입니다.
seasonality의 편차가 변동이 없습니다.
multiplicative model
Seasonality * Trends * Noise 형식을 가지며 비선형적입니다.
seasonality 변동성이 trend가 증가함에 따라 영향을 받아 증감된다는 특징이 있습니다.
AWS Athena
데이터를 로드할 필요없이 s3에 쿼리를 날릴 수 있는 서비스입니다.
CSV, JSON, Parquet, AVRO 포맷을 지원하며 기본적으로 SQL 쿼리를 실행할 수 있습니다.
Presto라는 오픈소스 엔진으로 운영되며 서버리스 서비스입니다.
비구조적, 반구조적, 구조적 데이터 모두 쿼리할 수 있습니다.
어떠한 서비스의 로그도 s3에 있다면 쿼리할 수 있고 다른 노트북과 통합할 수도 있으며 Quicksight를 통해 시각화도 가능합니다. ODBC, JDBC 프로토콜을 통해 모든 가상화 툴과 통합도 가능합니다.

Glue의 크롤러를 통해 메타데이터 리포지토리를 만들어 데이터 카탈로그를 저장합니다. 이를 통해 s3에 저장된 데이터의 스키마를 Athena에서 조회하여 데이터분석을 실행할 수 있습니다. 이후 Athena 쿼리를 QuickSight에 입력해서 시각화할 수 있습니다.
데이터를 Columnar 형식(ORC, Parquet)으로 포맷하면 30-90%의 비용과 성능을 향상시킬 수 있습니다.
Athena 쿼리 결과를 암호화도 가능하고 결과를 s3에 저장하여 버킷 정책을 이용할 수 있으며 항상 TLS가 사용됩니다.
QuickSight
쉽고, 빠르게 사용할 수 있는 클라우드 기반 비즈니스 분석 서비스입니다.
AWS나 다른 곳에 저장된 데이터를 기반으로 빠르고 쉽게 대시보드, 차트, 리포트를 만들어줍니다.
따로 대시보드나 커맨드라인을 관리할 필요없고 높은 수준의 애플리케이션 인터페이스를 제공하여, 데이터를 시각화시키고 어디에나 저장할 수 있습니다. → 다양한 차트와 그래프를 만드는 애플리케이션입니다.
Redshift / Aurora,RDS / Athena / ec2-hosted database / Files(excel, CSV, log format) 등 다양한 형식의 데이터를 소스로 활용합니다.
제한된 ETL을 허용해 Quicksight를 사용하면서 데이터를 변화시킬 수도 있습니다.
SPICE라는 인메모리 병렬 엔진을 사용하며 대규모 데이터 집합에서 사용할 수 있습니다.
머신러닝 인사이트라는 기능을 통해 머신러닝 알고리즘을 직접적으로 데이터와 연결해서 데이터를 분석할 수 있습니다.
Anomaly detection / Forecasting / Auto-narratives 등 인사이트를 통해 여러 대시보드를 만들 수 있습니다.
Quicksight Q
ML로 작동하고 Query문에 대해 자연어를 통해 작성할 수 있습니다.
“플로리다에서 가장 잘 팔리는 아이템은?”이라고 쿼리를 전달할 수 있는데 사전의 사용법을 익히고 데이터 셋에 대한 훈련이 필요합니다. 즉 데이터 셋과 관련된 주제를 설정해야 Q가 잘 작동할 수 있으며, 추가적으로 필드가 NLP 친화적이어야합니다.
Quicksight Paginated Reports
Quicksight 대시보드 기반 포맷이 잘 된 여러 페이지로 만들 수 있으며, 정기 보고서를 출력할 수 있습니다.
ETL 기능이 제한되있으므로 대규모 데이터셋에 작업한다면 Glue를 활용해야합니다
MFA, VPC 연결, RLS 같은 보안과 엑세스 규칙을 정의할 수 있으며 사용하는 플랜에 따라 필드에 대한 보안 제어가 가능해집니다. 네트워크 인터페이스, ENI, EX를 사용해 프라이빗한 링크를 설정할 수 있습니다.
사용자당 요금이 부과되므로 AWS IAM 혹은 이메일 / 로그인 프로세스를 통해 정의할 수 있습니다.
SAML 기반 SSO도 지원하며 Active Directory와 통합이 가능합니다.
경보나 이상 감지 기능 또한 지원합니다.
QuickSight Dashboards
데이터 집합에서 어떤 것을 얻고싶은지에 따라 어떤 시각화가 적합한지 알 수 있습니다.
AutoGraph
선택한 필드와 타입, 데이터 속성에 기반한 가장 적합한 시각화 유형을 사용합니다.
Bar Charts
비교 및 분포를 확인하기 위한 도구는 Bar 형태이며 히스토그램과 유사합니다.
Line graphs
시간에 따른 추세를 확인하기 위한 도구로 사용합니다.
Scatter plot, Heat maps
두 변수 간의 관계를 보여주는 도구로 사용되며 2차원 데이터를 추론하기 위한 도구로 사용합니다.
상관관계를 확인하기 위한 도구로 사용합니다.
히트맵은 2차원 데이터를 색상으로 표현하여 상관관계를 확인할 수 있습니다.
Pie graphs, Tree maps
집합으로 표현하기 위한 도구로, 그 중에서 트리맵은 계층적 데이터를 직사각형을 중첩시켜 표현합니다.
Pivot tables
2차원 데이터의 교차점에서 데이터를 요약하고 출력하는데 사용합니다. 거기에 통계적 함수를 적용할 수 있으며 다차원 데이터를 다룰 때 피벗테이블을 통해 통계함수를 적용할 수 있습니다.
새로 추가된 시각화 타입
KPI
원하는 값과 상대적인 값을 확인할 수 있습니다
Geospatial Charts(maps)
Donut Chats
파이차트의 일종으로 데이터 타입이 적을 때 유용합니다.
Gauge Charts
물체의 양이나 대역폭을 나타냅니다.
Word Clouds

EMR
EMR의 클러스터는 ec2 인스턴스의 집합입니다.
- 마스터 노드: 클러스터 관리 및 작업 조정을 담당합니다.
- 단일 마스터 노드를 통한 단일 노드 클러스터를 만들 수 있습니다.
- 코어 노드: 데이터 처리 및 HDFS 스토리지에 데이터를 제공합니다.
- 실시간 처리를 원한다면 코어 노드를 늘려 스트리밍 데이터를 처리하고 저장할 수 있습니다.
- 태스크 노드: 추가 처리 능력을 제공합니다.
- 단순한 컴퓨팅 파워만 제공하는 노드로, 작업이 실패해도 HDFS에 저장된 파일에 영향을 주지 않습니다.
Transient vs Long Running Clusters
클러스터에 작업 순서를 미리 정의하고 작업이 완료되자마자 자동으로 클러스터를 처리하여 돈을 절약할 수 있습니다.
장기 실행이 가능한 클러스터 또한 만들 수 있으며 애플리케이션과 주기적으로 상호작용을 위해 사용할 수 있습니다.
CloudWatch / S3 / CloudTrail / Data pipeline까지 스케쥴할 수 있습니다.
EMR Storage
- HDFS
저장하는 데이터를 분배하고 여러 개의 데이터를 저장하여 개별 인스턴스가 실패해도 데이터가 분실되지 않습니다. 기본적으로 HDFS의 블록크기는 128MB로 분히라여 유지하며 블록을 다른 3개의 노드에 복제합니다. 하지만 클러스터를 종료하면 로컬로 저장한 저장소도 함께 사라지게 됩니다. 대신 매우 빠르고 데이터에 엑세스하기위해 인터넷을 거치지 않습니다.
- EMRFS
s3를 마치 HDFS처럼 사용할 수 있게 해줄 수 있고 s3 Consistency를 통한 일관성을 위한 뷰도 있습니다. DynamoDB를 추가해서 일관성을 추적할 수 있습니다.
- Local File System
분산되지 않아 마스터 노드에서만 사용할 수 있습니다. 마스터 노드는 데이터를 필요한 곳으로 옮기는 역할을 하기 때문입니다.
- EBS
백업을 위해 사용할 수 있습니다.
EMR promises
- EMR 서비스 + ec2 비용이 시간당 청구됩니다.
- 코어노드가 실패하면 새로운 노드를 자동으로 프로비전하게 됩니다.
- 스팟인스턴스를 사용해 추가, 삭제가 자유롭습니다.
- 실행 중인 클러스터에서 코어 노드 사이즈를 변경할 수 있습니다.
Apache Spark on EMR

HDFS 아래에는 Hadoop Core 혹은 Hadoop Common이라고 불리는 Hadoop 모듈을 지원하는 공통 유틸리티 및 라이브러리의 모음이 있습니다. 그리고, Hadoop을 시작하는 데 필요한 JAR(Java Archive) 파일과 스크립트도 포함되어 있습니다.
HDFS
여러 인스턴스에 걸쳐 데이터가 분실되지 않도록 복사하지만 클러스터 종결 시엔 소실됩니다.
MapReduce 프로세싱 중 중간 결과 캐싱이나 임의적인 I/O가 있는 작업엔 상당히 유용합니다.
YARN
Hadoop v2.0부터 YARN을 통해 중앙집중식 자원관리와 작업 스케줄링으로 클러스터 리소스를 관리합니다.
이를 통해 MapReduce 말고 다른 것도 사용할 수 있게 해줍니다.
MapReduce
구글에서 만든 빅데이터 프로세싱을 위한 Map Reduce라는 알고리즘을 기반으로 만들어진 프레임워크로 클러스터에서 많은 양의 데이터를 병렬로 처리하고 실패에도 내성이 있습니다.
특징
- mapper 함수에 구성되어있습니다.
- 입력 데이터를 여러 개의 작은 블록으로 분할 한 뒤 각 블록을 mapper 함수로 매핑하여 처리합니다.
- 일반적으로 데이터를 변환, 포맷, 추출하여 중간 결과를 만들어냅니다.
- 중간 결과를 결합하는 Reduce 함수가 추가 알고리즘을 적용하여 최종 결과물을 만들어냅니다.Key-Value 데이터 그룹을 각각, 병렬로 처리하여 출력값을 도출합니다.키(Key)가 같은 맵 출력값은 모두 한 개의 Reduce 함수에 할당되고, 해당 함수가 그 Key의 값을 집계하여 결과를 리턴합니다.
mapper(데이터 변환/준비) → reduce(데이터 집약/정제)합니다.
최근에는 Apache Spark가 mapreduce를 대체하고 있으며 YARN을 통해 Spark는 HDFS를 사용하게 됩니다.
Apache Spark
- EMR 클러스터에 선택적으로 설치될 수 있고 오픈 소스 분산 프로세싱 시스템으로 보통 큰 데이터 작업에 사용됩니다.
- MapReduce보다 쉽고 메모리 캐싱을 적극적으로 활용하여 쿼리 실행을 최적화하여 빠른 분석을 제공합니다.
- 환경 또한 YARN HDFS에 국한되지 않고 쿠버네티스같은 다른 클러스터 관리자에서 실행이 가능하며 로컬 파일 시스템 등 다양한 데이터 소스에 엑세스할 수 있습니다.
- **Directed Acyclic Graph (DAG)**를 통해 더 영리하게 종속성과 프로세싱을 처리할 수 있고 효과적으로 스케쥴을 짤 수 있습니다.
- 자바, 스칼라 파이썬, R용 API가 있으며 여러 작업에 걸쳐 코드 재사용을 지원합니다. Batch 프로세싱, 양방향 쿼리, 실시간 분석, 머신 러닝, 그래프 처리가 가능하며 유즈케이스가 다양합니다.
- OLTP에는 잘 사용되지 않고 들어오는 데이터를 변환하는데 더 유용하게 사용됩니다.
Spark Engine
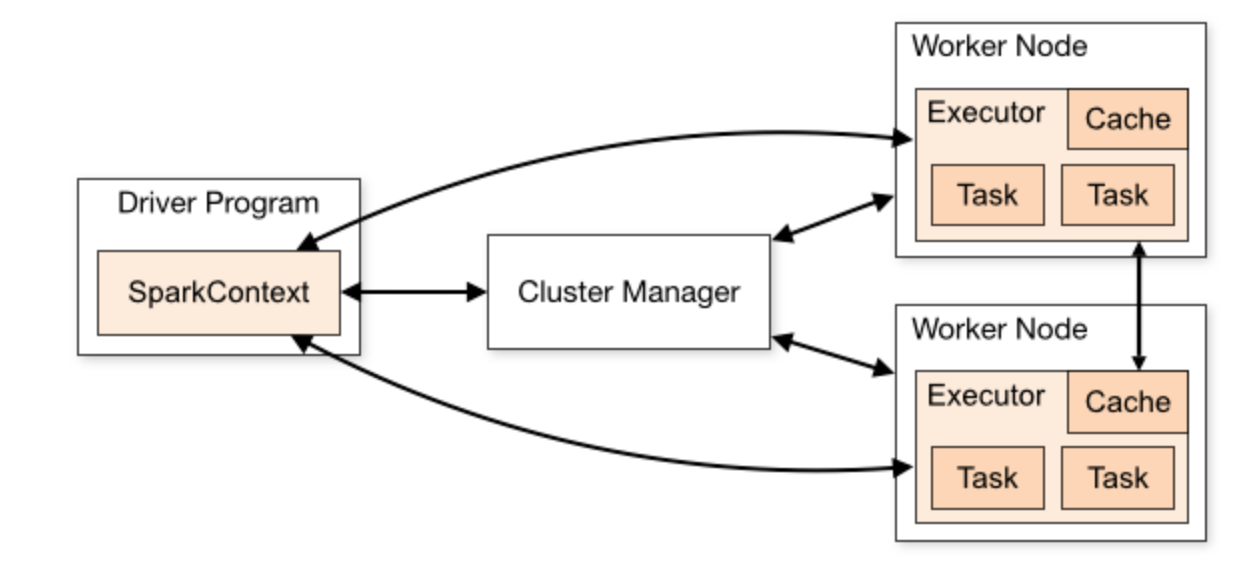
스파크 응용 프로그램은 클러스터 상에서 독립적인 프로세스 세트로 실행됩니다. Driver 프로그램은 스파크 컨텍스트 오브젝트가 조정되며 Spark job이 실행되도록하는 실제 코드적인 부분을 맡고 있습니다. Spark 컨텍스트는 다른 클러스터 관리자와 연결되는데 클러스터 관리자는 응용 프로그램 전체에 리소스를 할당하는 관리자로 자체 내장되어있습니다.
이를 통해 클러스터 노드에서 워커 노드를 확보하여 Executor라는 실행자를 확보합니다. 실행자는 응용 프로그램을 위해 연산을 실행하고 데이터를 저장하는 프로세스로 응용 프로그램에게 코드를 받은 뒤 Spark 컨텍스트에서 오는 작업을 실행합니다.
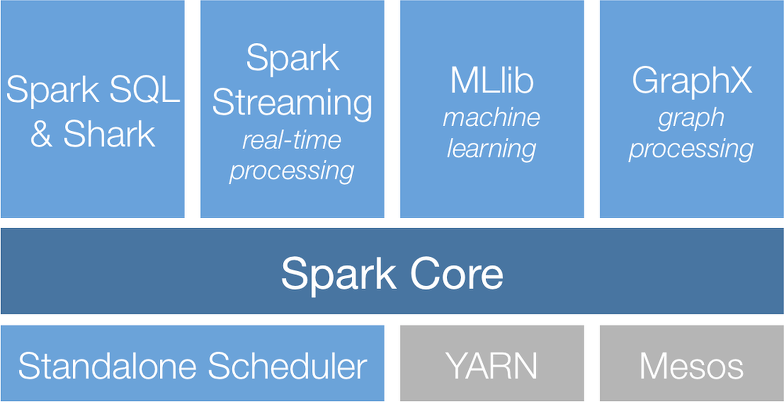
스파크 자체도 하둡처럼 부품이 다양하지만 근본은 스파크 코어에서 나오며 토대 역할을 합니다.
메모리 관리, 오류 복구 스케줄링, 배포, 모니터링 스토리지 시스템과의 상호작용을 책임지는 역할합니다.
또한 Java, 스칼라, Python, R을 위한 API가 있어, 최하위 레벨에선 탄력적 분산 데이터셋 또는 RDD를 사용합니다
자체적인 Spark SQL 관련된 레이어를 통해 다양한 데이터 소스르 지원하며 Python에서의 데이터 프레임 혹은 스칼라 데이터 셋을 보여줄 수 있습니다.
Spark 스트리밍을 통해 실시간 솔루션을 제공할 수 있습니다.이를 통해 빠른 스케줄링을 활용할 수 있고 배치 프로세싱에서 썼던 코드를 실시간 스트리밍에서 재사용할 수 있도록 만들 수 있으며 Kafka, MQ, HDFS같은 여러 서비스와 통합이 가능합니다.
중요한건 MLlib로 다른 AWS 서비스와 통합될 수 있습니다.

MLlib
- 개요: Spark MLlib은 간단함, 확장성 및 Spark와의 통합을 목표로 하는 Apache Spark의 스케일러블 머신러닝 라이브러리입니다. 다양한 머신러닝 알고리즘을 제공하여 분류, 회귀, 클러스터링 등을 지원합니다.
- 병렬 처리 및 워크플로우 유틸리티: MLlib은 Spark의 분산 컴퓨팅 아키텍처를 최대한 활용하여 효율적인 병렬 처리를 가능하게 합니다. 머신러닝 워크플로우 구축을 위한 도구들도 제공하지만 모든 머신러닝 알고리즘에 대한 병렬처리를 지원하진 않습니다.
데이터 시각화
- Matplotlib 및 Seaborn 통합: Spark 계산 결과는 Python의 데이터 시각화 라이브러리인 Matplotlib이나 Seaborn을 사용하여 시각화할 수 있습니다. 이는 일반적으로 Spark로 데이터를 처리 및 집계한 후 이를 시각화하는 과정을 포함합니다.
GraphX
- GraphX 개요: GraphX는 그래프 데이터를 대규모로 처리하기 위한 Spark의 API입니다. 그래프 생성, 변환 및 그래프 구조 데이터에 대한 추론을 가능하게 하는 다양한 연산자와 알고리즘을 제공합니다.
- ETL 및 양방향 변환: GraphX는 그래프 데이터에 대한 ETL 프로세스를 지원하며, 그래프의 생성과 변환을 위한 강력한 기능을 제공합니다.
EMR Notebook
Apache Zeppelin과 비슷한 컨셉으로 AWS 환경에서 통합되는 서비스입니다.
- 노트북은 s3에 백업되어있고, 노트북 안에서 전체 클러스터를 프로비저닝할 수 있습니다. → EMR 클러스터를 스핀업하고 해당 클러스터에서 태스크를 시작할 수 있습니다.
- VPC에서 호스팅되며 AWS 콘솔을 통해서만 엑세스가 가능합니다.
- EMR 노트북은 단순히 Apache Spark 응용프로그램을 만들어 클러스터에 쿼리를 실행하는 역할을 합니다.
- 파이썬, PySpark, 스칼라를 지원하며 인기있는 오픈 소스 그래픽 라이브러리로 포장되어 나와 코드 프로토타입을 통해 결과를 시각화 가능합니다.
- Spark 데이터 프레임으로 탐구 데이터 분석을 수행하도록 도와줍니다.
- 다수 사용자가 자신의 노트북을 만들어 공유 중인 멀티테넌트 EMR 클러스터에 연결하여 공동작업을 진행할 수 있습니다.
- EMR 사용자에게 추가적인 노트북 비용은 청구되지않습니다.
보안
- IAM 정책
- IAM 역할
- AutoScaling을 사용하는 경우 ec2에 대한 권한이 필요합니다.
- Kerberos
- Lakeformation을 통한 보안 구성을 지정할 수 있습니다.
- Apache Ranger(Hadoop 데이터 보안을 위한 오픈소스 툴)와 자체적인 통합
인스턴스 타입 선택
- 마스터 노드 : 큰 파워가 필요없습니다. 단순한 데이터 전달만 하기 떄문에 범용적인 m타입을 사용합니다.
- 코어 & 태스크 노드
- 웹 크롤러같은 외부 종속성이 있다면 t2.medium
- 단순한 성능 향상 : m타입 xlarge
- 연산이 많이 필요하다면: cpu 최적화 인스턴스
- 데이터베이스, 메모리 캐싱하는 애플리케이션 : 높은 메모리 인스턴스
- Network / CPU 집약적(NLP, ML) : 고성능 컴퓨팅 인스턴스
- 가속화된 컴퓨팅 / AI : GPU 인스턴스
- 스팟 인스턴스
- 태스크 노드를 위해 좋은 선택입니다.
- 데이터 손실을 감수하고 코어 혹은 마스터 노드에 적용할 순 있습니다.
Feature Engineering(기능 엔지니어링)
기능 엔지니어링이란 데이터를 적용하는 과정입니다. 사람의 속성을 가지고 10년 뒤 그 사람의 연봉을 예측하려고 한다고 가정해봅시다.
이런 경우엔 그 사람의 나이, 키, 체중, 주소부터 어떤 차를 모는지까지 다양한 데이터를 수집할 수 있습니다.
하지만 특정 데이터만 예측과 관련이 있기 때문에 기능 엔지니어링의 과정은 예측하려고 하는 것과 중요한 부분을 선택하여 변환하는 것입니다.
가공되지않은 데이터는 특정 모델에 유용하지 않기 때문에 정규화하거나 규모를 조정하는 등, 특정한 방식으로 인코딩 될 필요가 있습니다. 뿐만 아니라 누락된 데이터의 경우 그것을 처리하는 방법 등이 결과물의 큰 영향을 미칠 수 있기 때문에 단순히 가지고 있는 모든 데이터를 쏟아넣는다고해서 좋은 결과를 기대할 수 없습니다.
따라서 기능 엔지니어링은 ML에서 가장 중요한 부분이며, MLS 시험은 실제로 이 부분에서 경험이 있는지 없는지를 판가름하기 위한 시험이기도합니다.
차원의 저주 (Curse of dimensionality)
기능(특징/차원)이 너무 많으면 여러가지로 문제가 될 수 있습니다.
- 데이터의 부족
인간의 특징을 벡터로 변환할 수 있습니다.
나이, 키, 현재 연봉, 건강상태… 관련 항목의 특징을 추가하면 추가할수록, 점점 더 많은 공간을 추가할 수록 작업해야할 공간이 늘어나게 됩니다.
이렇게 공간이 넓어지게 된다면 최적의 해결책을 찾기 훨씬 어려워집니다. 그래서 기능이 많을수록 솔루션 공간 안에서 데이터가 더 띄엄띄엄 늘어나며 최상의 솔루션을 찾기 어려워집니다.
중요한 기능으로 줄이면 데이터가 덜 떨어져있고 올바른 솔루션을 찾기가 더 쉬워집니다.
따라서 어떤 게 통하고 어떤게 통하지 않는지 상식을 이용해서 모델을 개선해야합니다. 계속 효과를 확인하고 계속해서 개선해나가야 하기 때문에 해당 경험이 가장 중요하게 됩니다.
PCA, K-Means
차원 감소를 하는데 원칙적인 방법으로 기본 구성 요소 분석입니다.
모든 고차원적인 기능을 중요한 것들만 추려 더 적은 수의 기능으로 축소하는 방법입니다.
누락된 데이터
특징 엔지니어링의 큰 부분은 누락된 데이터를 제거하는 것 입니다.
품질의 큰 영향을 미치는 누락데이터를 처리하는 해결책은 여러가지 있습니다.
Imputation(전가)
사용 가능한 다른 데이터를 기반으로 누락된 값을 채우는 것입니다.
- 평균/중앙값/최빈값 대치: 누락된 값을 열에 있는 누락되지 않은 값의 평균, 중앙값 또는 최빈값으로 대체합니다.
- 예측 대치: 기계 학습 모델을 사용하여 다른 데이터 포인트를 기반으로 누락된 값을 예측하고 채웁니다.
빠르고 쉬우며 전체 데이터 셋의 평균이나 크기에 영향을 주지 않습니다.
하지만 컬럼 레벨에서만 작동하며 범주형 타입에는 적합하지 않습니다.동시에 상관관계가 있는 데이터를 잃어버릴 수 있습니다. 게다가 아웃라이어가 발생할 수 있습니다.
ex) 소득을 수집하는데 소득이 낮은 사람은 소득을 보고하지 않거나 숨기는 경우 데이터리스트에 부자들만 수집될 수 있습니다. 현상
Dropping
데이터 세트가 크고 누락된 데이터가 최소인 경우 누락된 값이 있는 행을 삭제할 수 있습니다.
마찬가지로 누락된 값의 비율이 높은 Column을 제거할 수도 있습니다.
가장 빠르고 쉽게 할 수 있는 방식입니다.
하지만 데이터를 투입할 떄 bias가 생길 수 있기 때문에 주의해야합니다.
혹은 비슷한 유형의 데이터가 있으면 데이터를 대치할 수 있기 때문에 좋은 방향을 생각하고 가장 효율적인 접근 방식을 사용하여야합니다.
K-NN(k nearest neighbours)
분류에서 사용되는 간단한 알고리즘으로 feature similarity를 사용해서 가장 닮은 데이터 K개를 찾는 방식입니다. 누락된 데이터와 가장 유사한 데이터 k 개를 찾아 해당 값의 평균 값으로 채워넣는 방식입니다.
카테고리 데이터같은 경우엔 사용하기 어렵습니다. 수치 데이터에 적합합니다.
Deep Learning
딥러닝 방식은 카테고리 데이터, 비수치적인 데이터에 DNN을 이용해서 머신러닝 모델을 학습하고 누락된 값을 유추하는 것 입니다.
단순히 누락된 컬럼에 대해 딥러닝을 돌리는 것과 유사하며 코드가 많이 필요하고 튜닝을 해야한다는 복잡성이 존재합니다.
Regression(회귀)
선형적 혹은 비선형적 관계를 찾을 수 있습니다. MICE라는 최신 방식을 사용하여 누락된 데이터를 여러 번 채우는 방식으로 작동합니다. 접근법이 유연하기 때문에 연속형, 이진형, 범위형 등등 여러 데이터 타입을 처리할 수 있습니다.
MICE(Multiple Imputation by Chained Equations)는 데이터세트에서 누락된 데이터를 처리하는 데 사용되는 통계 기법입니다. 이는 각 누락된 데이터 포인트를 데이터 세트의 다른 변수의 함수로 모델링하여 누락된 값을 대치하는 방법을 제공하는 다중 대치의 한 형태입니다.
데이터 더 넣기
누락된 데이터를 처리하기 위해 더 많은 데이터를 투입하는 방식입니다.
단순히 데이터를 많이 넣는 것보다 좋은 품질의 데이터를 넣는 것이 더 좋은 결과를 얻을 수 있으며 더 좋은 방법입니다.
불균형 데이터
불규형 데이터란 훈련 데이터 세트에서 한 클래스(예: 양성)의 사례 수가 다른 클래스(예: 음성)의 사례 수와 비교해 현저히 많거나 적은 경우를 말합니다. ex) 사기탐지
데이터 세트가 불균형하면 발생할 수 있는 문제로 더 많은 사례를 가진 클래스에 편향되게 학습되는 원인이 될 수 있으며, 이는 모델의 일반화 능력과 성능, 특히 소수 클래스를 정확하게 예측하는 능력에 부정적인 영향을 미칠 수 있습니다.
이때 양성과 음성은 용어 자체로 도덕적 잣대가 아니라 데이터의 감지 여부를 나타내는 플래그로써 사용됩니다.
해결방법
Oversampling
소수 클래스의 사례를 인위적으로 늘리는 방식입니다.
Undersampling
다수 클래스의 사례를 인위적으로 줄이는 방식입니다.
많은 양의 데이터가 있는 경우 합리적일 수 있습니다
SMOTE
소수 클래스의 오버 샘플링을 합친 방식으로 소수 클래스의 사례를 합성하여 추가함으로써 불균형을 개선하는 방법입니다.
KNN을 통해 이웃의 수치를 가져와 사례를 복사합니다.
따라서 데이터 균형이 맞지않는 경우 SMOTE가 가장 좋은 방법이 될 수 있습니다.
임계값 조정
거짓 양성이 너무 많으면 양성을 허용하는 임계값을 늘려 조정하게 됩니다.
거짓 양성(사기가 아닌데 사기라고 하는 경우)을 줄일 순 있지만 더 많은 거짓 음성(사기인데 사기가 아니라고 하는 경우)을 증가시킬 수 있습니다.
따라서 해당 임계값을 올릴 때 거짓 양성과 거짓음성의 비율을 확인하고 어느정도의 영향이 있을지 분석이 필요하며, 상황에 따라 개방적, 폐쇄적일 수록 효과적으로 사용할 수 있습니다.
아웃라이어 다루는 방법
variance
데이터 세트의 변동성을 측정하는 지표로 데이터 포인트들이 평균에서 얼마나 떨어져있는지를 나타냅니다. 이걸 계산하기 위해선 각 데이터 포인트(xi)에서 평균을 빼서, 각 데이터 포인트가 평균으로부터 얼마나 떨어져 있는지를 찾습니다. 이 차이를 (xi - μ)라고 합니다.
각 차이를 제곱하여, 음수가 되는 것을 방지합니다. (xi - μ)²
모든 제곱된 차이들의 평균을 계산합니다.
결과값은 데이터 세트의 변량(σ²)이자 데이터의 분포도를 의미하며 크면 클수록 데이터가 분포도가 넓다는 것을 의미하게 됩니다.

Standard Deviation(표준 편차)
variance에 제곱근을 취하면 표준 편차를 구할 수 있습니다.
표준편차는 데이터 포인트들이 평균값으로부터 얼마나 떨어져 있는지르 나타내는데 사용되며, 데이터의 분산 정도를 측정하는데 유용합니다.
표준 편차는 variance(변량)와 마찬가지로 데이터의 분산을 나타내지만, 데이터와 동일한 단위를 사용하기 때문에 해석하기 더 쉽습니다. 예를 들어, 길이를 측정하는 데이터의 경우, 변량은 제곱 단위(예: 제곱 미터)로 표현되지만, 표준 편차는 원래의 단위(예: 미터)로 표현됩니다. 이로 인해 표준 편차는 데이터의 분산을 직관적으로 이해하고 해석하는 데 더 적합합니다.
- σ는 표준 편차,
- σ2는 변량을 의미합니다.
아웃라이어를 처리하기
때로는 아웃라이어를 확인한 후 제거하는 것이 가장 적절할 수 있지만 때로는 그렇지 않습니다.
따라서 아웃라이어를 제거하는 것엔 책임감이 필요하며 왜 아웃라이어를 제거하거나 놔둬야하는지 이해하는게 중요합니디.
모든 영화를 보고 리뷰를 남기는 리뷰어의 영향이 다른 모든 사람의 영향보다 중요할 수 있지만, 누군가는 그것을 원하지 않을 수 있습니다.
특정 웹로그가 악의적인 트래픽을 보고할 수 있고, 봇일 수도 있고 그러한 측정 데이터를 확인해야할 수도 있습니다.
따라서 불필요한 가능성을 배제하고 숫자를 조작해야할 수도 있지만 모델로 삼으려는 목표와 일관성이 없다면 과감하게 불필요한 것들을 배제해야할 필요가 있습니다.
box-and-whisker diagram
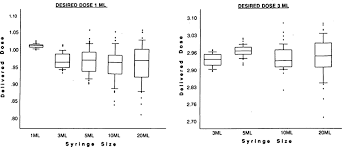
아웃라이어를 감지하고 시각화하는 방법이 내장되어있습니다.
Random Cut Forest
고유의 아웃라이어 알고리즘으로 Sagemaker, QuickSight, Kinesis Analytics, Opensearch 등 많은 AWS 서비스에서 사용되고 있습니다.
따라서 시험에서 아웃라이어 관련 언급이 생기면 RCF가 나올 수 있습니다.
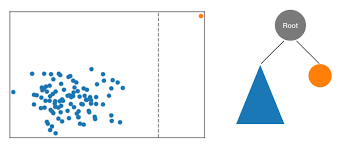
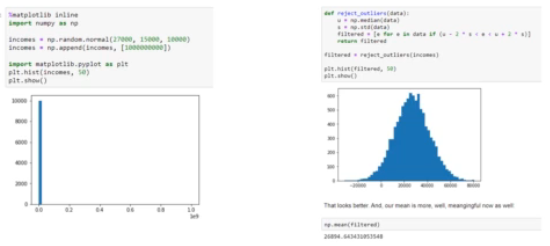
아래 예시에서 중앙값과 표준 편차를 벗어나는 값을 삭제하여 표본을 구할 수 있지만 과연 해당 아웃라이어를 제거하는게 옳은건지 계속되는 고민이 필요합니다.
기능엔지니어링에서 사용할 수 있는 기술
Binning / Bucketing
수치 데이터를 범위에 따라 특정 범주로 분류하는 방식으로 연속형 변수를 이산형 범주로 변환하는 기법입니다.
대표적으로 22.333333333333살이든 22.0살이든 모두 20대로 분류할 수 있습니다.
데이터의 복잡성을 줄이고, 머신러닝 모델의 성능을 향상시키며, 특히 비선형 관계를 갖는 데이터에 유용할 수 있습니다
- 모델의 복잡성 감소: 연속형 변수를 이산형 범주로 변환함으로써 모델의 복잡성을 줄일 수 있습니다.
- 노이즈와 이상치 영향 감소: 노이즈가 있는 데이터나 이상치의 영향을 줄일 수 있습니다.
- 비선형 패턴 탐지: 비선형 관계를 갖는 변수에 대해 모델이 더 잘 작동하도록 도울 수 있습니다.
따라서 불확실한 치수, 정확한 치수를 감추고 수치 데이터 뿐만 아니라 범주적 데이터에 기반한 모델을 사용할 수 있게 해줍니다.
하지만 특정 정보를 버리게 될 수 있습니다.
Quantile binning
데이터를 배포의 위치에 따라 분류하는 방법으로 데이터가 치우친 경우나 데이터의 분포를 정규화하고 싶을 때 특히 유용합니다. 각각의 상자 안에 동일한 수의 샘플이 있도록 하는 방식으로 동일한 수의 표본이 있도록 데이터를 잘 분배해야합니다.
Transforming
데이터의 분포나 규모를 변경하기 위해 수학적 연산이나 함수를 데이터에 적용하여 특정 알고리즘에 더 적합한 데이터 형식으로 만드는 과정입니다. 비선형적 데이터를 선형적으로 만들어 트렌드를 파악할 수 있고 왜곡을 감소시켜 정확도를 향상시킬 수 있습니다.
Encoding
특정 모델은 특정한 데이터 포맷을 요구하기 떄문에 모델이 요구하는 방식으로 인코딩해야합니다.
One-hot encoding
각 범주형 값에 대해 고유한 이진(0 또는 1) 컬럼을 생성하는 방식입니다. 이 방법은 범주형 변수를 머신러닝 알고리즘이 이해할 수 있는 형태로 변환하는 데 사용됩니다.
예를 들어, “색상”이라는 범주형 변수가 “빨강”, “파랑”, “녹색”의 세 가지 값을 가진다고 가정해 보겠습니다. One-hot encoding을 적용하면, 각 색상에 대해 별도의 컬럼이 생성되고, 각 데이터 포인트는 해당되는 색상의 컬럼에서만 1의 값을 가지게 됩니다.
- 빨강: [1, 0, 0]
- 파랑: [0, 1, 0]
- 녹색: [0, 0, 1]
딥러닝 뉴런에 입력되어 각 범주만을 보여주게 됩니다. 다만 많은 수의 범주를 가진 변수를 one-hot encoding하면, 매우 많은 수의 컬럼이 생성될 수 있어 모델의 성능을 저하시키고, 계산 비용을 증가시킬 수 있습니다.
Scaling / Normalization
거의 대부분의 모델에서 사용되는 방식입니다. 대부분의 모델은 데이터가 정상적으로 0 주변에 분산되는 걸 선호하며, 딥러닝과 신경망에서도 마찬가지입니다.
데이터의 범위가 큰 경우(사람의 소득)와 작은 경우(사람의 나이) 데이터를 비슷한 크기로 정규화되지 않으면 큰 숫자가 훨씬 큰 영향을 미치게 되며 결과 모델의 성능이 떨어질 수 있습니다.
Python의 경우 사이킷런에 미니맥스 스케일러를 통해 쉽게 조절하고 롤백할 수 있습니다.
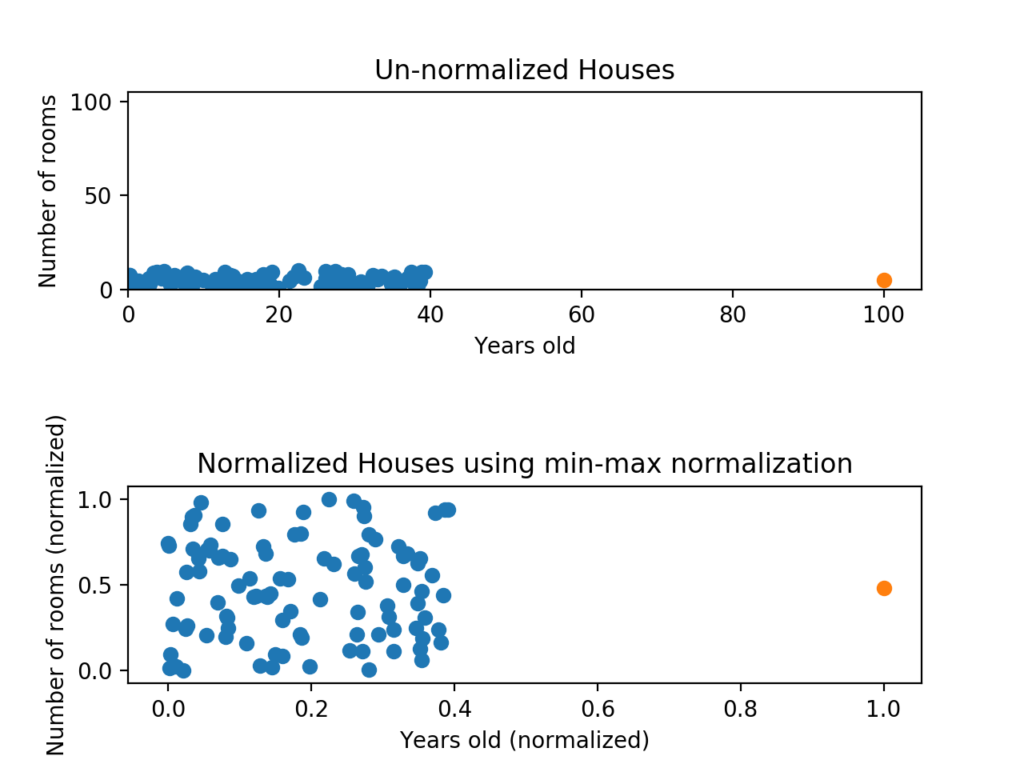
Shuffling
훈련 데이터를 수집한 순서에 따라 영향을 받을 수 있기 때문에 데이터를 섞어 순서를 임의로 설정함으로써 데이터를 수집하는 과정에서 발생하는 부산물을 제거할 수 있습니다. 이를 통해 품질도 달라지는 경우가 있으며 데이터를 섞기만해도 나은 결과를 도출할 수도 있습니다.
Ground Truth
주로 모델이나 알고리즘의 예측 결과를 평가하고 검증하기 위한 기준으로 사용됩니다. 수동 혹은 자동화된 도구를 사용하여 모델의 정답을 예측하곤 합니다.
하지만 누락된 데이터 측면에서 사람이 쉽게 추론할 수 있는 값일 경우 사람이 직접 누락된 데이터를 채워넣기도 하며 가장 흔한 예는 이미지 분류입니다.
라벨링과는 개념이 조금 다른데 라벨링은 명확한 정답이라고 하면, ground-truth는 우리가 정한 정답이다.(펭귄탈을 쓴 사람이 있을 때, 정답은 펭귄이 될 수도 있고 펭수가 될 수도 있다. 우리가 펭귄이라고 적게된다면 ground-truth가 된다)
사람이 하는 것 말고도 훈련용라벨을 생성하는 AWS 서비스들이 있으며 Rekognition Comprehend 등을 사용할 수 있습니다.
Ground Truth Plus
AWS에서 사람을 고용해 전체 프로젝트를 관리하는 Turnkey 솔루션입니다.
얼마나 진행됐는지 추적할 수 있고 시각화 또한 가능합니다.
데이터셋 준비(TF-IDF)
TF-IDF(Term Frequency-Inverse Document Frequency)는 정보 검색과 텍스트 마이닝에서 문서 내 특정 단어의 중요도를 평가하기 위해 사용되는 통계적 척도입니다. 이 방법은 문서 집합에서 단어의 빈도와 역문서 빈도를 결합하여, 단어가 문서 내에서 얼마나 중요한지를 수치적으로 나타냅니다.
특정 단어가 자주 발생하는 빈도를 측정할 수 있지만 실제 방법에는 미묘한 차이가 있습니다.
실제로는 단어가 크게 분산되기 때문에 단어를 측정하기 위해선 기록해야합니다. 기록을 위해 역인덱스를 사용하여 기록하여 인기 단어에 대해 분석을 효율적으로 만들어줍니다.
한계
단어 사이의 관계, 시제, 줄임말, 오타, 순서, 대소문자 등 이것을 모두 묶어 숫자로 매핑하는 것은 매우 어렵습니다. 이러한 문제를 해결하기 위해 Apache Spark를 사용할 수 있으며, bi-grams 혹은 n-grams를 사용할 수 있습니다.
앞에 두 개를 잡을지, 세 개를 잡을지 조합을 선택하게 됩니다.
TF-IDF는 이러한 말뭉치를 묶어 매티릭스를 구체화하는 것이고, 구체화를 통해 각 문서와 개별 기간에 대한 TF-IDF값을 계산하는 것이 목적입니다.
이를 통해 간단한 검색 알고리즘을 만들 수 있고 주어진 검색어를 통해 TF-IDF 점수를 정리하여 결과를 확인할 수 있습니다.

EMR Studio and Spark를 활용한 TF-IDF 테스트
EMR serverless를 통해 여러 사람이 접근하여 협업도 진행가능합니다. EMR serverless에 경우 클러스터 문제가 있어서 안되면 다시 생성하여 진행해야합니다.